A Sprint Retrospective
The IT Ops team’s 4th sprint came to its conclusion recently… and we delivered all of our commitments! Huzzah! This post is basically a summary of how we analysed the sprint and what we got up to in the retrospective.
The main objectives of this sprint were:
- Rolling out a new password policy
- Rolling out a new file server
- Rebuilding the dev db
In addition to these tasks there were a bunch of other smaller tasks, far too dull for me to list here.
This was the first time we’d completed all of our committed points, and it gave us enough information to work out how many points we can realistically attempt to deliver in each sprint.
Once again the team completed over 100 points in the sprint, and once again we committed to doing 50 project points (the other 50-or-so being unplanned interruptions).
Sprint 4 in Numbers:
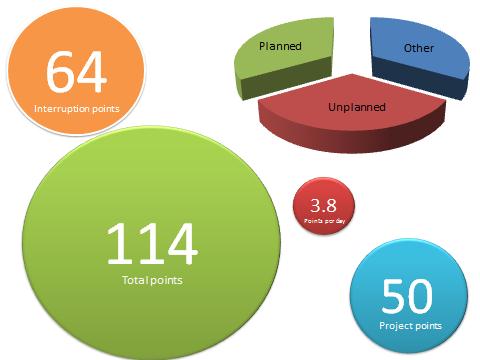
We completed 50 committed points
We completed 64 unplanned points
Total: 114 points
That’s very much in-line with the total we’ve come to expect.
We averaged 3.8 points per person per day for the duration of the sprint.
This means that we’re able to do roughly 2 points per person per day on committed project work.
In an ideal scenario, with no interruptions, no meetings and nothing to distract us from our tasks, we estimate that we could do about 6 points per person per day.
Therefore, statistically speaking, were actually 33% productive on our project work.
Of the remaining 67% we spent another 33% on interruptions.
So what happens to the other 33%??
The remaining effort and time is taken up with meetings, discussions, unrecorded interruptions, emails, phone calls and unproductive time. This figure (33%) is in the region of what I expected before we embarked upon this process some 8 weeks ago.
How to use this information
Well we know that we can complete approximately 50 project points per sprint. So we can now break down upcoming projects into tasks, and give realistic predictions on when they can be delivered.
The only caveat is that we do not make guarantees on project priority. We will always commit to working on delivering the highest business value projects first, and as a result will take guidance from the business on priorities. If a project’s priority is lowered then it will likely drop down the pecking order of our tasks, and its delivery date will slip.
In short, providing project priorities don’t chance for the duration of the project, we can now give far more realistic predictions on delivery dates.
Retrospective
To get the creative juices flowing, we started the retrospective with everyone drawing a picture of Sprint 4. There were no rules to this task, we could draw anything we wanted that represented sprint 4 for us as individuals.
Here’s the resulting “artwork”, if you can call it that:

Farid, who for some reason I expected to be something of an artist, drew a picture of the Jules Rimet trophy. This was partly to represent the fact that we completed the Password and File server projects, and partly to reflect that we hit our target.

Nick’s “effort” was of a question mark going into a grinder with a gold bar coming out of the other end. This reflects the fact that we’re not 100% sure of what’s happening up front at the beginning of our sprint, and we base our estimations on “best-guesses”, but by the end of the sprint we were producing the goods. It also raises a very relevant point about how we know we are addressing the right projects/tasks in the right order. More on that later.

Jon (in his unique avant-garde style) drew a person wearing a Boss hat. The person represents the team, and the boss hat is representative of the fact that we all completed our tasks on time and delivered what we committed to. Or at least that was his explanation, although I suspect it has more to do with the Lonely Island “Like a Boss” video, which is something of a theme tune in the IT Ops team. Seriously.
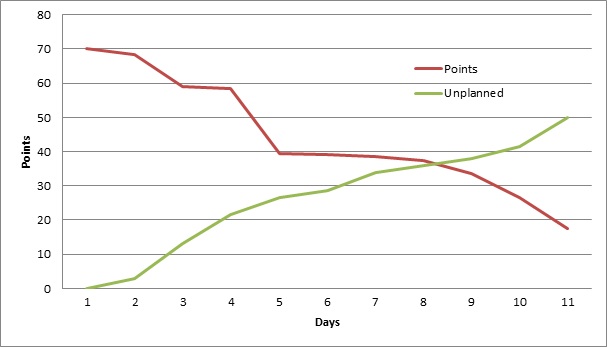
Leo drew the burndown, the original of which you can find at the bottom of this post.
Next up, we all chose 1 thing from the sprint that we wanted to discuss in more detail. Here’s what we ended up speaking about:
1. Using small post-it notes to record interruptions on the board didn’t work. They’re too small and not sticky enough. This was a major issue for Leo and Jon, who clearly have something against post-it notes.
2. We need to plan more carefully. Our planning sessions are rushed, and as a result we don’t think our tasks through as well as we should. The main failure here is that we don’t think about the impact other people can have on our tasks.
Following this, we discussed what we think went well, and what we think went badly in the sprint:
WENT WELL
- Better prioritisation of interruptions allowed us to concentrate on the
- committed tasks
- Implementing the password policy
- Realistic goal setting
WENT BADLY
- IT request backlog grew bigger
What did we learn from Sprint 4:
- 50 Project points is our magic number
- Don’t over-commit
- Do more forward planning
- Our prioritizing is getting better
Finally we discussed the stats and figures mentioned earlier, and then we looked back at the burndown to see if there was any useful information we could take from it.
Leo suggested that the burndown be pre-populated with the mean line, so that we can see our daily deviation from that line. I have filed this suggestion in a folder named “Leo’s Good Ideas”, and we’ll adopt it in future sprints once I’ve worked out how to use Excel properly (or found a pen and a ruler).
The Burndown

Improvements
As mentioned earlier, we’ve worked out what our average velocity is – and we can now confidently say that 50 project points per sprint is a realistic target for the team. Now that we’ve established this, we need to turn our attention to ensuring that we’re delivering the highest business value we possibly can. At present we feel we are slightly deficient in engaging with the business to define our priorities, so in the future we’ll be looking at having a much closer engagement with the rest of the business to help us with our prioritising and acceptance criteria. We want to be delivering the most important projects first, and we want to have a clear picture of what a successful delivery of those projects looks like.
Over the next couple of sprints we’ll be shifting our focus in this direction, and hopefully people will start to see the results over the next few weeks.
P.S. Jon is available for hire as a short order artist, ideal for weddings and birthday parties. Disappointment guaranteed.